Predicción de salud infantil en Argentina - parte 2/2
En el post anterior hablaba de una competencia Kaggle en la que teníamos que construir un modelo para predecir ciertos factores que afectan a la salud de los niños en Argentina. Hice un poco de análisis exploratorio sobre el problema y hoy sigo por la misma línea, ahora aplicada a un modelo.
Datasets
En el episodio anterior(?), vimos que tenemos algún tipo de “historia” de cada paciente: tenemos algunas filas que corresponden al mismo paciente y a chequeos diferentes. Ahora podemos intentar construir otro conjunto de datos que aproveche esta “historia del paciente”.
En el training set, tenemos algunos pacientes con cuatro chequeos y el resto solamente tiene tres chequeos. Para esos con sólo tres mediciones, la cuarta medición la podemos encontrar en el test set. Si agarro todos los pacientes con cuatro checkeos en el train set, puedo concatenarlos en una sola fila.
Ahora tenemos un dataset hecho de la historia de cada paciente, usando los cuatro chequeos por cada fila.

Por ejemplo, dado un paciente, puedo buscar sus cuatros checkeos y concatenarlos en una sola fila. La clara ventaja de esto es que, en cada fila, tengo mucha más información sobre el paciente: todas las HAZ. WAZs, BMIZs, etc en una sola fila. Estoy dejando afuera a aquellos pacientes que solo tienen tres checkeos porque no tengo informacion de la variable “decae” para ese cuarto checkeo (porque vive en el test set). A su vez, esto significa que ahora tengo un train set mucho más chico, 6200~ contra el original de 42000~.
Otra cosa que puedo hacer es, en lugar de concatenar los cuatro chequeos, concateno solo tres por fila como en la imagen. Esto implica que ahora puedo usar los checkeos 1, 2, 3 de cada paciente y usar esos pacientes que antes no pude porque no necesito ese cuarto checkeo. Con este enfoque tengo el doble de filas de entrenamiento, 12000~.
También mantuve el conjunto de datos original para usar en el entrenamiento. Supongo que no puede ser malo entrenar un modelito separado con ese.
Desde ahora le pongo nombre a estos datasets: 4-dataset, 3-dataset y dataset original, respectivamente.
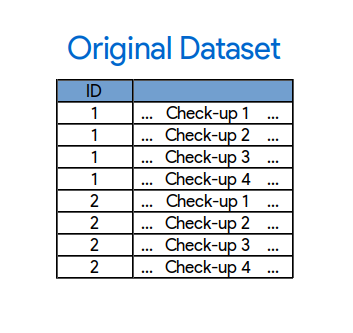 Dataset original: uno por fila
Dataset original: uno por fila
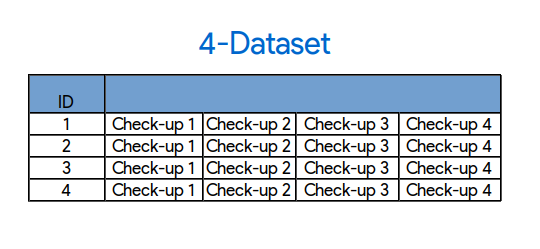 4-dataset: una fila con cuatro checkeos
4-dataset: una fila con cuatro checkeos
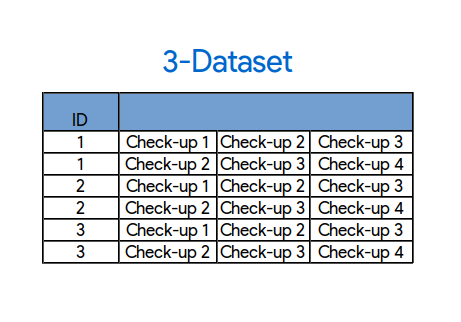 3-dataset: dos filas por cada paciente
3-dataset: dos filas por cada paciente
Estos son los tres datasets principales que voy a usar en mi solución final, pero en el trayecto hice muchos otros experimentos (fallidos) .
Ahora también es el momento de darle agregarle un par de cosas más a nuestro pipeline (recuerden que teníamos un pipeline funcionando end to end desde el último post). Con scikit-learn podemos dividir automáticamente los datasets de training en tres partes: train/test/validation. Esto va a terminar siendo muy práctico porque dejamos el test set original sin tocar, lo que significa que no vamos a estar overfitteando a esos datos.
Otra cosa básica para tener es un método de cross-validation (también viene casi gratis en scikit) para tener una estimación de nuestro score localmente.
Corrí cada dataset en nuestro pipeline básico de a uno a la vez, y al submittear la solución para el 4-dataset resultó en un score de 0,785. La última puntuación fue 0,77043, así que es una linda mejora!
Sacando features de la galera
Ok, tenemos nuestro pipeline funcionando, exploramos nuestros datos, hicimos mapitas y nuevos datasets. ¿Ahora que? Podemos empezar a buscar nuevos features y transformar los existentes en una mejor representación para el clasificador.
Las features que voy a agregar se basan en los datos del mapa de los que hablamos en el último post, combinaciones de las features originales e ideas de otros estudios que encontré sobre el mismo tema. Algunos de estos funcionaron sin problemas y otros fueron terribles.
Empecemos con los datos del mapa de vimos antes. Usé lo que se veía esa vuelta en el mapa, clustericé “a mano” los hospitales y terminé creando catorce regiones diferentes.
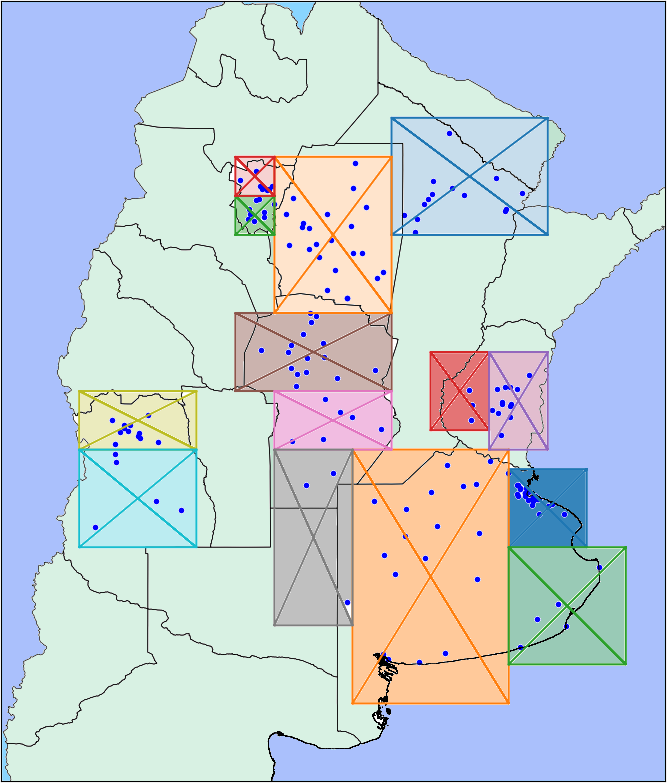
Parecía una buena idea en principio, pero lamentablemente no funcionó para nada. El Gradient Descent que estoy usando como modelo, te deja ver qué features fueron las más importantes en el momento de tomar una decisión. Este nuevo clustering terminó por no ser importante en absoluto.
Por otro lado, otro enfoque que consiste en tener el ratio de “decae” = true/false por cada hospital fue bastante bueno. Esta feature mejoró la puntuación en general.
En el 4-dataset, tenía cuatro casos de HAZ, WAZ y BMIZ en el tiempo. Quise usar esta información, y dejar saber al clasificador que esos valores están relacionados de alguna manera. Empecé con una función que, para cada fila, ajusta una regresión lineal sobre estos cuatro valores y agrega la pendiente y la ordenada al origen como nuevas features.
Acá pueden jugar un poco con algunos de los resultados:
Patient ID: [[{curr+1}]]
Decae: [[{datasets[curr][12]}]] [[{datasets[curr][12]}]]
También agregué features polinómicas de segundo grado basadas en HAZ, WAZ y BMIZ. Esto significa tomar cada una de las features y multiplicarlas por todas las demás (incluyendo a sí misma). En mi caso particular, en el 4-dataset por ejemplo, combiné HAZ_1, …, HAZ_4 en las siguientes features:
Apliqué la mism idea para WAZ_1…WAZ_4 y BMIZ_4…BMIZ_4. Con esto generé 30 nuevas features en total.
El problema de la competencia en cuestión, el de salud y crecimientos en los niños, debe ser uno común y tienen que existir otros artículos y papers sobre el tema. De hecho, hay muchos. Éste en particular me llamó la atención porque trata de resolver un problema muy parecido pero en niños de Etiopía. Usé un resultado de ese paper: una regla que decía que un individuo está desnutrido si
and
con la desviación estándar.
Ellos afirman que esta regla clasificó correctamente el 99,7% de sus casos (!). Esto parece un poco mágico, así que ¿por qué no?, Vamos a intentarlo. Ajusté un poco esos valores y creé una feature basada en esa regla que, por falta de un mejor nombre, se llama “magia”. Terminó siendo una de las features más importantes de mi modelo.
| Nombre | Descripción |
|---|---|
| region_n | 1 si el hospital pertenece a la región , 0 si no. |
| p | proporción de decae=true para ese hospital |
| HAZ_x * HAZ_y | Funciones polinómicas para HAZ |
| WAZ_x * WAZ_y | Funciones polinómicas para WAZ |
| BMIZ_x * BMIZ_y | Funciones polinómicas para BMIZ |
| HAZ/WAZ/BMIZ_x_linear_reg_slope | Pendiente de la línea de regresión para HAZ/WAZ/BMIZ |
| HAZ/WAZ/BMIZ_x_linear_reg_intercept | Ordenada al origen de la línea de regresión para HAZ/WAZ/BMIZ |
| magic | and |
Combinando todo
Hasta ahora, estuve corriendo cada uno de estos datasets por separado y submitteando esas soluciones. Una idea en machine learning que funciona muy bien es “combinar” varios modelos más chicos en un modelo mejor. Hay diferentes enfoques para hacer esto como boosting, bagging o stacking. En nuestro modelo base, Gradint Boosting, ya usa esta idea al tener un ensamble de árboles internamente.
Para combinar mis modelos usé stacking. Esto significa hacer un nuevo conjunto de datos a partir de las soluciones de otros modelos y correr otro clasificador encima de eso.
<a class='fancybox-thumb ' id="model1" title="Modelos independientes y sus predicciones"
data-thumb="/assets/eci/model1.png" href="/assets/eci/model1.png" rel="models">
<img alt="model1" src="/assets/eci/model1.png">
<span class="fancy-caption">Modelos independientes y sus predicciones</span>
</a>
<a class='fancybox-thumb ' id="model2" title="Modelo de stacking final"
data-thumb="/assets/eci/model2.png" href="/assets/eci/model2.png" rel="models">
<img alt="model2" src="/assets/eci/model2.png">
<span class="fancy-caption">Modelo de stacking final</span>
</a>
Entonces, ¿qué estoy combinando acá? Como dije, estuve corriendo cada uno de los datasets descritos con un simple algoritmo de Gradient Boosting. Lo que voy a hacer ahora es obtener todas esas predicciones y hacer un nuevo conjunto de datos con cada predicción como una columna y voy a correr un nuevo algoritmo de predicción para tener el resultado final.
Bueno, por ahora tenemos tres datasets: 4-dataset, 3-dataset y el original. Pero puedo dar un par más de vueltas sobre esto. Recordemos la definición de la variable objetivo:
| Decae |
Es "True" si por lo menos una de las siguientes condiciones se cumple:
{
HAZ >= -1 and next_HAZ < -1
WAZ >= -1 and next_WAZ < -1
BMIZ >= -1 and next_BMIZ < -1
|
Ok, algo que podemos ver es que todo depende del valor del chequeo anterior: si HAZ/WAZ/BMIZ estaba por debajo de -1 (la primera parte de la condición), “decae” siempre será falso sin tener en cuenta el valor de el próximo chequeo. Esto parece muy restrictivo y probablemente confunda un poco al algoritmo.
¿Qué pasa si saco esta restricción? Para cada uno de mis datasets hice otro donde “decae” no tiene la restricción. Esto significa que “decae” será independiente de los valores anteriores y sólo dependerá del nuevo checkeo. Tenía tres datasets y los dupliqué así que ahora tengo conjuntos de datos.
Después, hice armé otros datasets, pero en vez de sacar la restricción para todas las variables, la quité para una variable a la vez. Por ejemplo, hice un nuevo dataset sacando la restricción sobre HAZ pero sin tocar WAZ y BMIZ. Eso son tres conjuntos de datos más por cada uno de los originales: .
Una última idea, puedo intentar predecir “decae” usando sólo una columna del dataset original a la vez. Por ejemplo, puedo tratar de predecir “decae” sólo mirando la fecha de nacimiento, luego mirando sólo a la región del hospital, etc. Cada una de estas predicciones por sí misma es muy mala, pero combiné los resultados en un nuevo dataset, teniendo cada predicción en una columna. Sí, es la idea de stacking otra vez, hice un modelo de stacking más chico para usar en nuestro último modelo de stacking más grande.
Esto lleva el total a dieciséis modelos diferentes. Como dije antes, puse cada una de las predicciones de los dieciséis modelos como columnas de un nuevo dataset final y usé otro modelo de predicción sobre eso (que terminó siendo Gradient Descent de nuevo, pero con otros hiperparámetros).
Este decimoséptimo modelo fue el último.
Ajustando parámetros
Finalmente, vamos a mejorar y optimizar todo. Tengo diecisiete modelos hechos de Gradient Boosting con parámetros por defecto. Este algoritmo tiene varios hiperparámetros para jugar y creo que este es el momento para empezar con esta tarea. Tengo la impresión de que es bastante común (y yo mismo lo hice también…) empezar a ajustar los parámetros muy temprano cuando se trabaja en un proyecto, incluso antes de tener un pipeline de punto a punto funcionando (hablé un poco acerca de esto anteriormente). El problema con esto es que se puede perder mucho tiempo tratando de mejorar algo que va a cambiar deprisa. Por lo tanto, me gusta tener una solución sólida y bien pensada antes de empezar a optimizar.
Encontrar hiperparámetros es básicamente un proceso automatizado. Scikit tiene métodos como GridSearchCV o RandomizedSearchCV. El primero busca en todas las combinaciones de los parámetros, haciendo cross-validation y reportando el mejor conjunto de parámetros que encontró. Es leeeeento.
RandomizedSearchCV en cambio no intenta todo, sino que se especifican cuántas veces se desea que corra el algoritmo y se elige un subconjunto al azar de los parámetros en cada vuelta. Es mucho más rápido pero me fue lo suficientemente bueno en mi caso.
Entonces se me ocurrió un método propio que me funcionó. No sé si es algo que ya existe y acabo de reinventar la rueda o algo así. O tal vez es nomás una mala idea en general y tuve suerte esta vez. El método es una búsqueda greedy sobre el espacio de hiperparámetros:
- Para cada parámetro del modelo, asigno un conjunto de valores posibles
- Tomo uno de los parámetros al azar
- Intento todos los valores posibles asignados a ese parámetro y fijo el valor que obtuvo la mejor puntuación
- Continúo desde (2) con ese parámetro fijo en su valor
Corro esto veces y mantengo el mejor modelo generado. Sí, ya sé, como mínimo suena un poco turbio pero en la práctica funcionó para mí y fue muy rápido (si no me equivoco, con n el número total de valores que puedo probar para los hiperparámetros).
Corrí esto hasta que me parecieron que los resultados eran lo suficientemente buenos y después submitié.
Mi score anterior fue de 0.785 y mi score final… * redoble de tambores *….0.78998.
Conclusión
Terminé la competencia 18vo de los 40 participantes. No es el puesto que me hubiera gustado, pero está bien y aprendí mucho en el camino:
-
Tener un pipeline de punto a punto como primera prioridad resulta ser bueno. Pero después de hacer eso, habría querido mirar un poco mejor los datos. Por ejemplo, la próxima voy a intentar clasificar a mano algunos ejemplos para ver si se puede descubrir un patrón o mirar los casos más extremos de cada clase. El cerebro resulta ser más poderoso que cualquier predictor algorítmico.
-
Puedo reutilizar mi código para otra competencia, creo que al menos la estructura es utilizable y puedo ahorrar bastante tiempo.
-
El modelo de stacking funciona bien, pero me costó mucho codearlo. La próxima vez voy a pensar el código mejor, sabiendo que voy a tener que usar los resultados parciales para un modelo de stacking.
-
Por último, tengo mi método de cross-validation casero no tan científicamente probado, pero bueno en la práctica que me ayudó esta vez. Puede que no sea la mejor alternativa, pero me encariñé.
Lo interesante de este problema es que estos resultados (y los de los otros participantes) pueden ser útiles en salud pública. Con más información, como por ejemplo datos sobre las madres, seguramente se pueda tener un mejor score y mejores predicciones.
Sería buenísimo si algo como esto termina siendo usado por los médicos y se pueda ayudar a los chicos antes de que incluso empiecen a tener algún tipo de problema.
Eso es todo, gracias por leer!